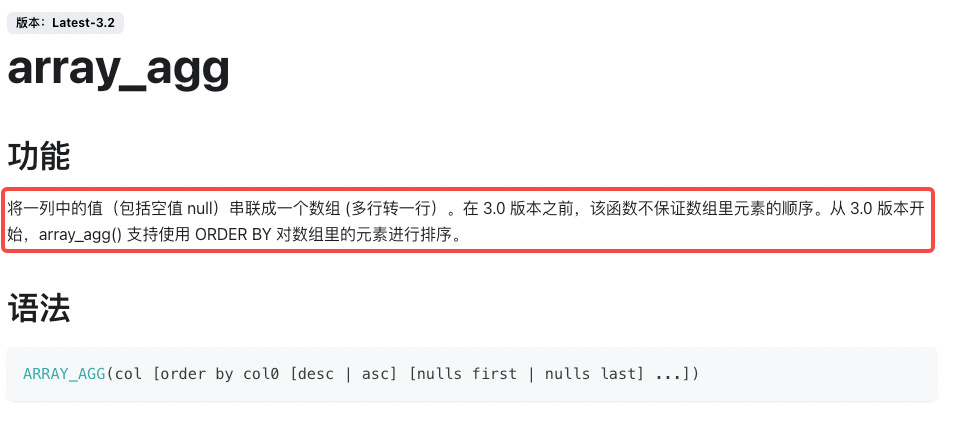
我是从一个源表清洗数据到另外一个维度表 我跑了3次数据 我sum了一个金额指标 每次都不一样
建表语句:
CREATE TABLE app_user_revenue (
day date NULL COMMENT “”,
ad_id varchar(200) NULL COMMENT “”,
app varchar(200) NULL COMMENT “”,
ad_revenue_unit varchar(200) NULL COMMENT “”,
ad_revenue_network varchar(200) NULL COMMENT “”,
ad_revenue_placement varchar(200) NULL COMMENT “”,
app_version varchar(200) NULL COMMENT “”,
ad_type varchar(200) NULL DEFAULT “unknown” COMMENT “”,
scene_name varchar(200) NULL DEFAULT “unknown” COMMENT “”,
statusvpn varchar(200) NULL DEFAULT “unknown” COMMENT “”,
id bigint(20) NULL COMMENT “”,
package_name varchar(200) NULL COMMENT “”,
idfa varchar(200) NULL COMMENT “”,
revenue float NULL DEFAULT “0” COMMENT “”,
impressions int(11) NULL COMMENT “”,
ad_id_name varchar(200) NULL COMMENT “”,
country_code varchar(200) NULL COMMENT “”,
create_by varchar(200) NULL COMMENT “”,
update_by varchar(200) NULL COMMENT “”,
update_time datetime NULL COMMENT “”,
del_flag varchar(65533) NULL DEFAULT “0” COMMENT “”,
created_at bigint(20) NULL DEFAULT “0” COMMENT “”,
create_time datetime NULL COMMENT “”,
match_count int(11) NULL DEFAULT “0” COMMENT “”,
req_count int(11) NULL DEFAULT “0” COMMENT “”,
click_count int(11) NULL DEFAULT “0” COMMENT “”
) ENGINE=OLAP
UNIQUE KEY(day, ad_id, app, ad_revenue_unit, ad_revenue_network, ad_revenue_placement, app_version, ad_type, scene_name, statusvpn)
PARTITION BY date_trunc(‘day’, day)
DISTRIBUTED BY HASH(day)
PROPERTIES (
“replication_num” = “1”,
“in_memory” = “false”,
“enable_persistent_index” = “false”,
“replicated_storage” = “true”,
“compression” = “LZ4”
);
查询源表语句:
SELECT
day,
array_agg(DISTINCT idfa)[1] as idfa,
ad_id,
sum(revenue_usd) AS revenue_usd,
sum(ad_impressions_count) AS ad_impressions_count,
array_agg(DISTINCT package_name)[1] as package_name,
array_agg(DISTINCT ad_id_name)[1] as ad_id_name,
app,
app_version,
array_agg(DISTINCT country_code)[1] as country_code,
ad_revenue_unit,
ad_revenue_network,
ad_revenue_placement,
app_version,
ad_type,
scene_name,
statusvpn,
array_agg(DISTINCT created_at)[1] as created_at,
COUNT(CASE WHEN event_name = ‘ad_req’ THEN 1 END) AS reqCount,
COUNT(CASE WHEN event_name = ‘ad_match’ THEN 1 END) AS matchCount,
COUNT(CASE WHEN event_name = ‘ad_click’ THEN 1 END) AS clickCount
from
source_user_adjust
where
day BETWEEN '2024-03-07' and '2024-03-07'
and (activity_kind = 'ad_revenue'
or event_name in('ad_req', 'ad_click', 'ad_match'))
group by
day,
ad_id,
app,
ad_revenue_unit,
ad_revenue_network,
ad_revenue_placement,
app_version,
ad_type,
scene_name,
statusvpn
创建ROUTINE LOAD:
CREATE ROUTINE LOAD kafka_xx ON talbe
PROPERTIES
(
“format” = “json”
)
FROM KAFKA
(
“kafka_broker_list” = “localhost:9092”,
“kafka_topic” = “kafka_topic”,
“property.kafka_default_offsets” = “OFFSET_BEGINNING”,
“property.group.id” = “group”
);