
mysql+canal+kafka+SparkStreaming+StarRocks
环境:
集群已有mysql+zookeeper+kafka,未有组件请自行百度安装~~~
mysql
确认mysql是否开启binlog
show variables like '%log_bin%';
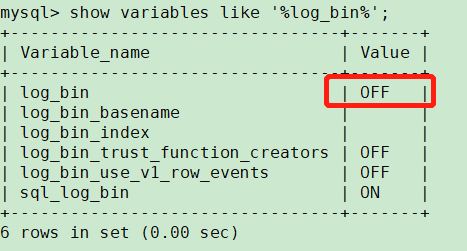
未开启binlog
vim /etc/my.cnf 添加以下内容
server_id=1918
log_bin = mysql-bin
binlog_format = ROW
expire_logs_days = 7
max_binlog_size = 100M
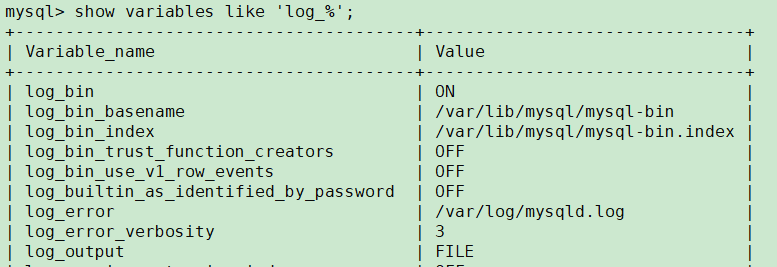
重启mysql再次查看相关参数
CREATE USER canal IDENTIFIED BY '123456';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
CREATE DATABASE canal;
安装canal
下载安装
安装目录:/home/disk1/sr/app/canal-1.1.4
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
解压后目录如下:
- bin # 运维脚本
- conf # 配置文件
canal_local.properties # canal本地配置,一般不需要动
canal.properties # canal服务配置
logback.xml # logback日志配置
metrics # 度量统计配置
spring # spring-实例配置,主要和binlog位置计算、一些策略配置相关,可以在canal.properties选用其中的任意一个配置文件
example # 实例配置文件夹,一般认为单个数据库对应一个独立的实例配置文件夹
instance.properties # 实例配置,一般指单个数据库的配置
- lib # 服务依赖包
- logs # 日志文件输出目录
配置编辑
编辑canal.properties文件 vim conf/canal.properties
去掉canal.instance.parser.parallelThreadSize = 16
这个配置项的 注释 ,也就是启用此配置项,和实例解析器的线程数相关,不配置会表现为阻塞或者不进行解析。
canal.serverMode 配置项指定为 kafka ,可选值有 tcp 、 kafka 和 rocketmq ( master 分支或者最新的的 v1.1.5-alpha-1 版本,可以选用 rabbitmq ),默认是 kafka 。
canal.mq.servers 配置需要指定为 Kafka 服务或者集群 Broker 的地址,这里配置为 127.0.0.1:9092
编辑instance.properties文件 vim conf/example/instance.properties
canal.instance.mysql.slaveId
#需要配置一个和
Master
节点的服务
ID
完全不同的值,这里配置为
654321
。
配置数据源实例,包括地址、用户、密码和目标数据库:
canal.instance.master.address #这里指定为 127.0.0.1:3306 。
canal.instance.dbUsername #这里指定为 canal 。
canal.instance.dbPassword #这里指定为123456。
新增 canal.instance.defaultDatabaseName #这里指定为canal(需要在 MySQL 中建立一个 test 数据库,见前面的流程)。
Kafka 相关配置,这里暂时使用静态 topic 和单个 partition :
canal.mq.topic #这里指定为canal test , 也就是解析完的 binlog 结构化数据会发送到 Kafka 的命名为 test 的 topic 中 。
canal.mq.partition #这里指定为 0 。
配置修改完成后启动canal
Sh bin/startup.sh
DDL操作
use `canal`;
CREATE TABLE `order`(
id BIGINT UNIQUE PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
order_id VARCHAR(64) NOT NULL COMMENT '订单ID',
amount DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '订单金额',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', UNIQUE uniq_order_id (`order_id`)) COMMENT '订单表';
INSERT INTO `order`(order_id, amount) VALUES ('10086', 999);UPDATE `order` SET amount = 10087 WHERE order_id = '10086';DELETE FROM `order` WHERE order_id = '10086';
查看canal日志
Tail -30f /home/disk1/sr/app/canal-1.1.4/logs/canal/example/example.log 日志如下
(刚开始有个错误mysql链接失败的截图忘了截图,排查cs01集群的mysql,无法用密码登录,确认密码无误,卡了半天最后发现mysql库里的user表有两行user和authentication_string是空,导致任何一个用户都无法用密码登录。。。只能免密登录,确认两个空行是无用信息后删除了,这个卡了好久!!!参考资料:https://www.cnblogs.com/zhaoxd07/p/5580543.html)
解决mysql问题后example.log日志如下,已经正常读取binlog。
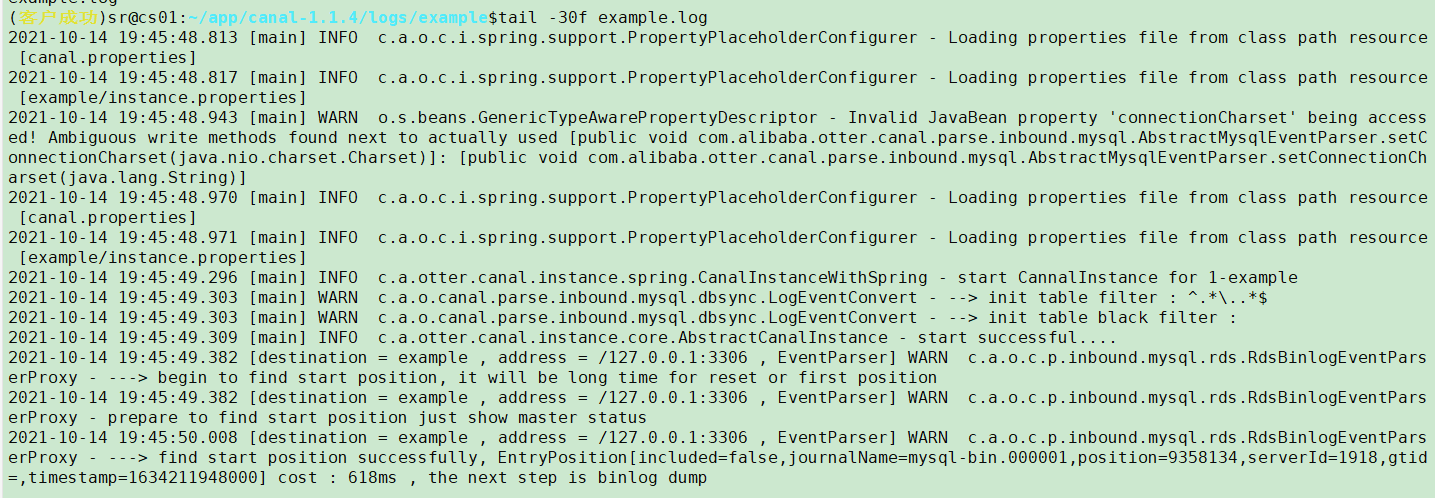
另一个日志报错显示无法连接kafka:
Tail -30f /home/disk1/sr/app/canal-1.1.4/logs/canal/canal.log

去查kafka配置文件
vim /home/disk1/sr/app/kafka_2.12-2.5.0/config/server.properties

修改canal配置文件相应参数 vim canal.properties
canal.mq.servers = xxx:9092
重启canal查看日志

忘了创建topic
cd /home/disk1/sr/app/kafka_2.12-2.5.0/bin
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic canaltest
创建分区后日志已不刷新上述错误
查看kafka topic数据
sh /home/disk1/sr/app/kafka_2.12-2.5.0/bin/kafka-console-consumer.sh --bootstrap-server 172.26.194.184:9092 --from-beginning --topic canaltest
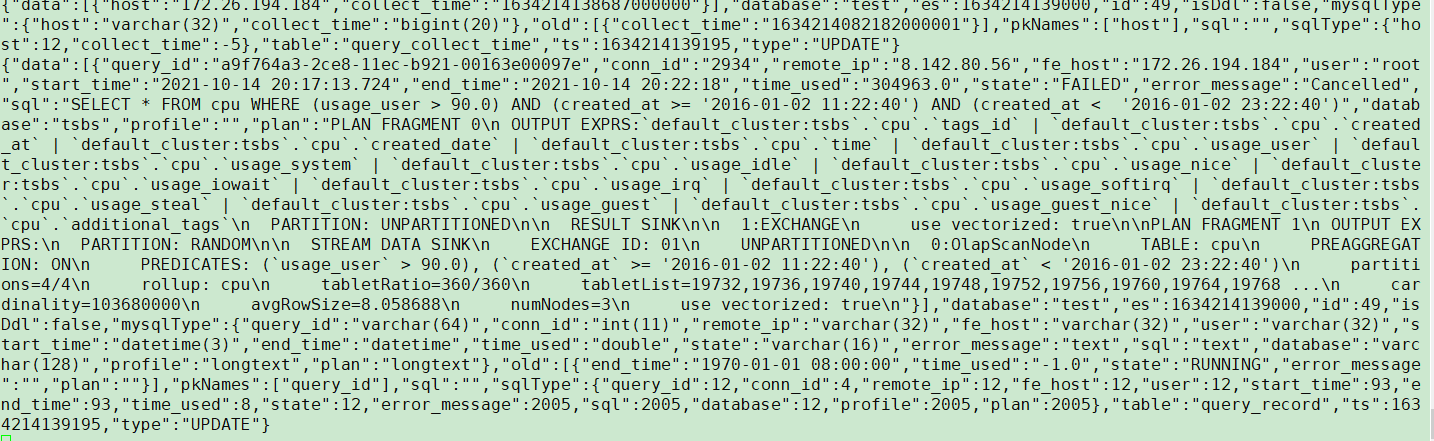
数据已成功写入kafka
安装maven
官网地址: http://maven.apache.org/download.cgi下载apache-maven-3.8.3-bin.tar.gz
## 上传到/usr/local
cd /usr/local
## 解压
tar -zxvf apache-maven-3.8.3-bin.tar.gz
## 配置环境变量
vi /etc/profile
export MAVEN_HOME=/usr/local/apache-maven-3.8.3
export PATH=$MAVEN_HOME/bin:$PATH
## 刷新环境变量
source /etc/profile
SparkStream2StarRocks
导入样例数据:
{“data”:[{“host”:“172.26.194.184”,“collect_time”:“1634257382332000000”}],“database”:“test”,“es”:1634257382000,“id”:1466,“isDdl”:false,“mysqlType”:{“host”:“varchar(32)”,“collect_time”:“bigint(20)”},“old”:[{“collect_time”:“1634257102008000000”}],“pkNames”:[“host”],“sql”:"",“sqlType”:{“host”:12,“collect_time”:-5},“table”:“query_collect_time”,“ts”:1634257382785,“type”:“UPDATE”}
DDL
CREATE TABLE sparkstreamig(
`database` varchar(50) NULL COMMENT "",
`es` varchar(50) NULL COMMENT "",
`id` varchar(50) NULL COMMENT "",
`table` string NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`database`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`database`) BUCKETS 3
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
代码构建:
https://github.com/StarRocks/demo fork到自己仓库 https://github.com/qcydorisdb/demo
修改SparkStreaming2StarRocks.scala文件中的database,topic,brokers等信息,示例如下:
SparkStreaming2StarRocks.scala (5.0 KB)
mkdir project
cd project
## clone修改后的文件到服务器
git clone https://github.com/qcydorisdb/demo
cd demo/SparkDemo
编译
mvn clean scala:compile compile package
启动spark 程序
cd /home/disk1/qichaoyang/project/demo/SparkDemo
java -cp target/SparkDemo-1.0-SNAPSHOT-jar-with-dependencies.jar com.starrocks.spark.SparkStreaming2StarRocks
执行任务报错:

分析:database列和table列是关键词导入失败,
修改SparkStream2StarRocks内容,columns添加反引号。
修改前:
val columns = "database,es,id,table"
val database = jsObj.getString("database")
val es = jsObj.getString("es")
val id = jsObj.getString("id")
val table = jsObj.getString("table")
修改后
val columns = "`database`,`es`,`id`,`table`"
val `database` = jsObj.getString("database")
val `es` = jsObj.getString("es")
val `id` = jsObj.getString("id")
val `table` = jsObj.getString("table")
再次编译并执行demo
cd /home/disk1/qichaoyang/project/demo/SparkDemo
mvn clean scala:compile compile package
java -cp target/SparkDemo-1.0-SNAPSHOT-jar-with-dependencies.jar com.starrocks.spark.SparkStreaming2StarRocks

插入成功。
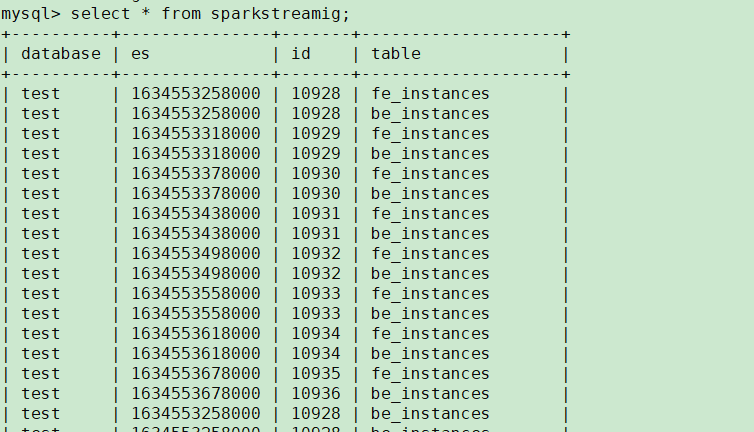
查询表数据:
参考资料:
https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart