

各位 StarRocks 的新老用户:
StarRocks 近期发布了 2.2 版本,核心更新有:支持资源隔离,提供 Java UDF 框架,提供 JSON 数据类型,支持 Apache Hudi 外表,数据湖分析优化,主键模型支持部分列更新等。查看完整的 release note 请点这里。
以下是详细介绍,欢迎您升级使用、多多反馈!
资源隔离
资源隔离一直是用户呼声最高的需求之一,在 2.2 版本中我们发布了 Resource group(资源组)的功能。通过资源组,我们可以给大查询和小查询设置不同的资源组,给不同资源组配置不同的 CPU 和内存资源,从而大大降低不同负载在同一个集群执行时的相互干扰。在我们的测试集中,对小查询的响应延迟有 2-4 倍的提升,明显优于没有使用资源组的版本,部分场景接近物理隔离的效果。
另一方面,通过 Pipeline 引擎我们也在资源组中实现了弹性调度的能力。在集群空闲的时候,查询会充分利用资源,当集群负载变大时,资源组会按照比例伸缩至原有的资源,这样可以获得比物理隔离更好的资源利用率。
相关文档参见:https://docs.starrocks.com/zh-cn/main/administration/Resource_Group
Java UDF 框架
虽然 StarRocks 已经提供了很多类型的函数,但是用户仍然需要用到各种处理特殊的逻辑,特别是在做 ETL 时。StarRocks 2.2 中提供了 Java UDF 框架,包括 Scalar Funciton、Aggragate Function、Window Function、Table Function 都可使用用户自定义的函数来实现,这样用户可以在 StarRocks 上更好地进行自定义的功能扩展,包括可以迁移一些来自 Hadoop 生态的 UDF 处理逻辑。
相关文档参见:https://docs.starrocks.com/zh-cn/main/using_starrocks/JAVA_UDF
JSON 数据类型
做数据分析时,数据可能来自传统结构化数据的 TP 数据库,也会来自 Server 日志、物联网数据、App 打点等等。业务的多样性和变化性,使得静态 Schema 在一些场景下的使用会变得很麻烦:当业务有较多增减列、有嵌套数据结构、数据稀疏、列类型不确定等情况下,不仅开发人员需要较多的维护操作,数据导入衔接也会存在较多的问题。
JSON 类型的数据是一种半结构化数据,它层次清晰、结构灵活、易于阅读和处理,是解决这些问题的好方式。使用 JSON 类型来存储和处理后,上游业务只管根据业务需要在 JSON 类型列中随意增减 Key/Value,下游数据分析人员只管按需要查询 JSON 数据,数据开发人员也不再需要做任何 Schema change 等变动。
StarRocks 2.2 版本中预发布了JSON 一期功能:提供 JSON 类型,用二进制方式代替之前 JSON 格式的字符串,使得性能提升至原来的 2 倍;同时也提供了更多 JSON 函数,包括 JSON_EACH 这种 Table function。
相关文档参见:https://docs.starrocks.com/zh-cn/main/sql-reference/sql-statements/data-types/JSON
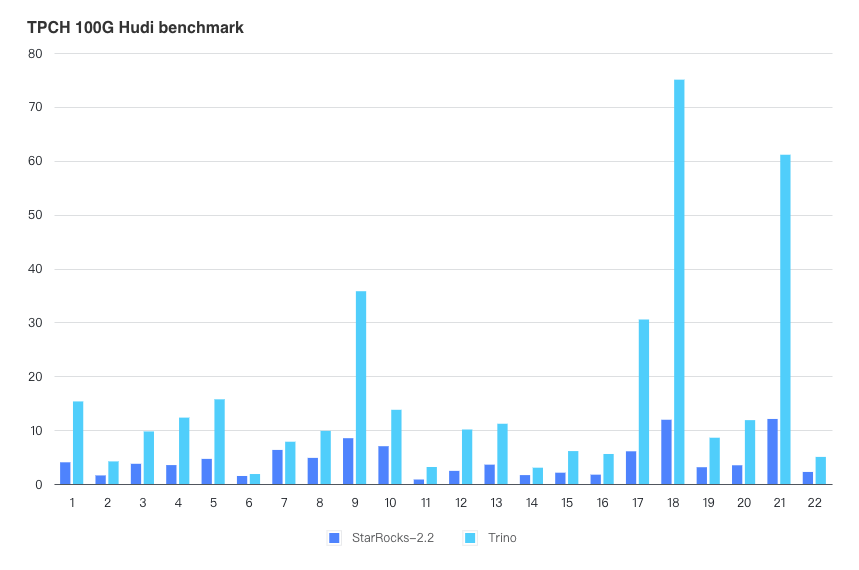
Apache Hudi 外表
阿里云开源大数据团队在 StarRocks 2.2 版本中又贡献了面向 Apache Hudi 的外表特性,进一步扩展了 StarRocks 在数据湖上的分析能力,支持 Copy on Write 表的高效查询,支持 Parquet/ORC 等数据文件格式,同时也支持 HDFS/S3/OSS 等存储方式。
在相同机器的测试环境下,根据 TPCH 100G 数据集的测试,StarRocks-2.2 是 Trino-358 性能的 3.69 倍,测试结果如下图所示:
数据湖分析优化
越来越多的用户还是基于对象存储来构建数据湖生态,因此在 2.2 中我们优化了 Apache Hive 外表中基于对象存储(Amazon S3、阿里云 OSS)的外部表的性能,优化后基于对象存储的查询性能可以与基于 HDFS 的查询性能基本持平。另外,通过支持 ORC 格式文件的延迟物化,降低了一些过滤度高的查询 IO,还针对一些真实用户场景中小文件过多的问题进行了查询优化。
在元数据方面,支持更新通过定期消费 Hive Metastore 的事件(包括数据变更、分区变更等),实现自动增量更新元数据。这样可以避免 Hive 表的分区数据更新或者增加列以后需要手动 refresh table 和重新建表的问题。
相关文档参考:https://docs.starrocks.com/zh-cn/main/using_starrocks/External_table#自动增量更新元数据缓存
另外还支持查询 Apache Hive 中 DECIMAL 和 ARRAY 类型的数据。
主键模型支持部分列更新
Primary Key 模型支持了部分列更新功能,已经可以通过 Stream load / Broker load / Routine load 对宽表的部分列进行实时更新。在订单实时更新、多流实时 JOIN 等场景下,使用部分列更新的功能可以降低实时更新任务的处理复杂性,不需要用户维护额外的窗口,也不需要去额外的读取不需要更新的数据。
相比之前在聚合模型中使用 replace_if_not_null 的聚合方式,去除了查询阶段的 sort merge,大幅提升了查询性能。但是当前版本使用部分列更新的表不推荐超过 100 列,而且需要 SSD 盘来支持更高的随机 IO。
相关文档参见:https://docs.starrocks.com/zh-cn/main/loading/PrimaryKeyLoad#部分更新
其他特性与优化
- 支持了array_agg 、array_sort、array_distinct、array_join、reverse、array_slice、array_concat、array_difference、arrays_overlap、array_intersect 等函数,可以通过这些数据的函数实现各种灵活的数据操作,同时也可以实现 group_concat(distinct / order by) 等函数功能。
- 支持了 Retention 函数,可以方便地计算留存类指标。
- 重构 CBO 优化器的 Parser 和 Analyzer,优化代码结构并支持 Insert with CTE 等语法,提升复杂查询的性能,包括公用表表达式(Common Table Expression,CTE)复用等。
- 优化 UNION ALL 算子性能,性能提升可达 2-25 倍。
- 发布 Pipeline 引擎,支持自适应调节查询的并行度,并且优化了 Pipeline 引擎的 Profile,提升了高并发场景下小查询的性能。
- 导入 CSV 文件时,支持使用多个字符作为行分隔符。
在这个版本中, 57 位贡献者共提交 817 个 Commits,感谢他们:
@mofeiatwork @Linkerist @meegoo @trueeyu @dirtysalt @sevev @Youngwb @Astralidea @kangkaisen @liuyehcf @stdpain @xiaoyong-z @chaoyli @decster @HangyuanLiu @Seaven @stephen-shelby @gengjun-git @ZiheLiu @silverbullet233 @Pslydhh @mchades @ABingHuang @satanson @wangruin @rickif @wyb @miomiocat @laotan332 @adzfolc @DorianZheng @wuleistarrocks @johndinh391 @caneGuy @sduzh @karan-kap00r @wanpengfei-git @creatstar @xlwh @Gabriel39 @Ielihs @DeepThinker666 @hffariel @SaintBacchus @bigdata-kuxingseng @blackstar-baba @staman96 @Johnsonginati @zbtzbtzbt @Gri-ffin @jsinwell @aaawuanjun @DebayanSen96 @RishiKumarRay @Ccuurryy @wuqiao @screnwei