【详述】有一张9亿的非分区表(OLAP表,6桶),尝试了2个SQL,如下:
sql1:select hld_dt,sum(t.hld_val + t.accr_intr) as cn from fin_prd_hld_info t group by t.hld_dt; --返回365rows,总耗时:3s707ms
sql2:select hld_dt,sum(t.hld_val + t.accr_intr) as cn from fin_prd_hld_info t where t.hld_dt >= 20210101 and t.hld_dt <= 20211231 group by t.hld_dt; --返回365rows ,总耗时:4s387ms
【背景】无特殊操作
【业务影响】
【StarRocks版本】2.1.2
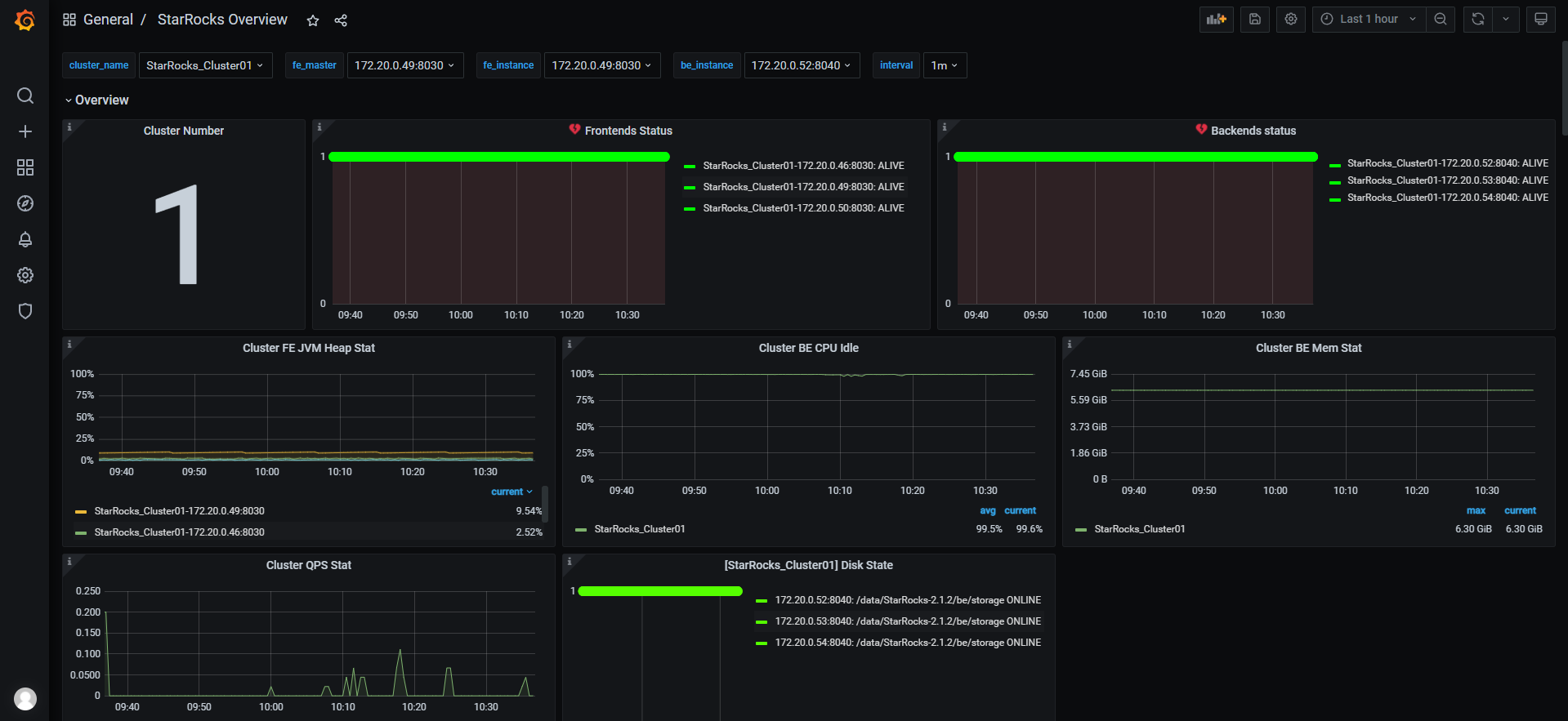
【集群规模】3个BE,3个FE,1Master+2follower(8c16G)+ 3broker(broker与fe混合部署,be单独部署),共6个节点
【机器信息】CPU虚拟核/内存/网卡,例如:BE(16c64G)/万兆,FE(8c16G)/万兆
【附件】
- fe.warn.log/be.warn.log/相应截图
- 慢查询:
- Profile信息sql1profile (40.3 KB) sql2profile (40.9 KB)
- 并行度:8
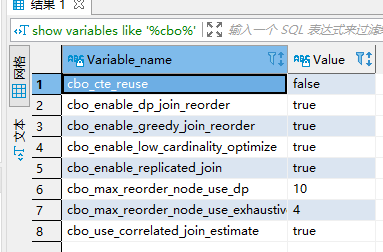
- cbo是否开启:show variables like ‘%cbo%’;
- be节点cpu和内存使用率截图