
【starrocks 集群信息】
版本:1.19.5
节点:3 个 FE,3 个 BE
【背景】
创建了 routinue job 后,指定了 kafka 的分区和 offeset 点。创建成功后正常运行,但是 kafka 那边的数据一致在堆积,没有被消费,查看 progress 发现 offset 点没有变化!
【日志信息】
kafka 消费记录:
routine 运行状态:
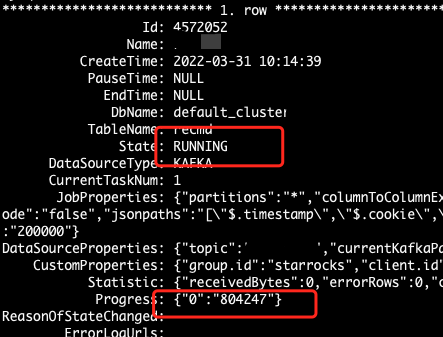
【疑问】
1、为什么 routine job 创建成功,但是无法消费?
2、如何去定位问题(哪些日志可以查看)?
3、遇到这种问题,怎么去快速解决呢?
