starrocks版本:1.19.5
集群规模:3fe+5be 其中一台fe与be混部
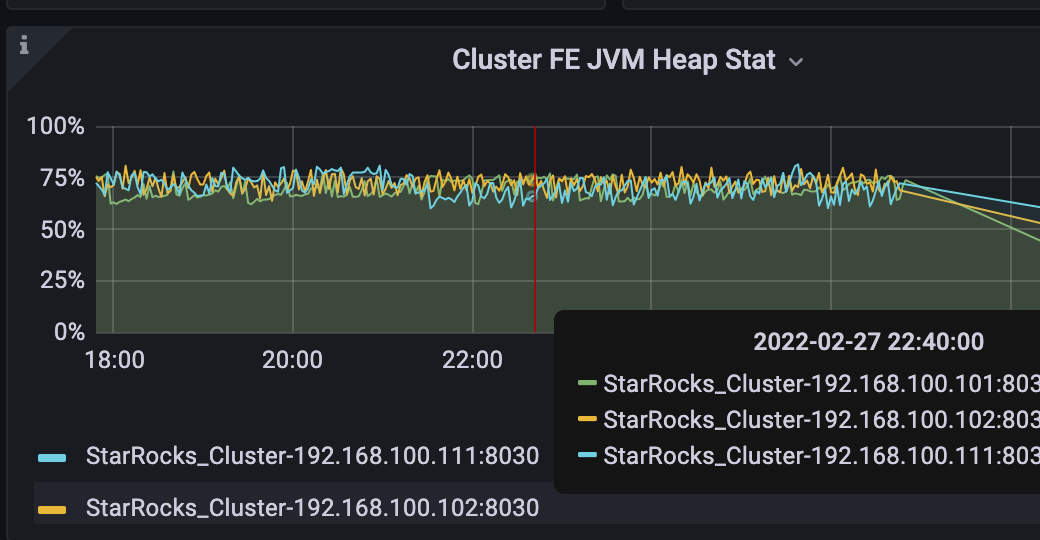
因为监控显示fe jvm head占用高,所以调大参数后滚动重启fe,
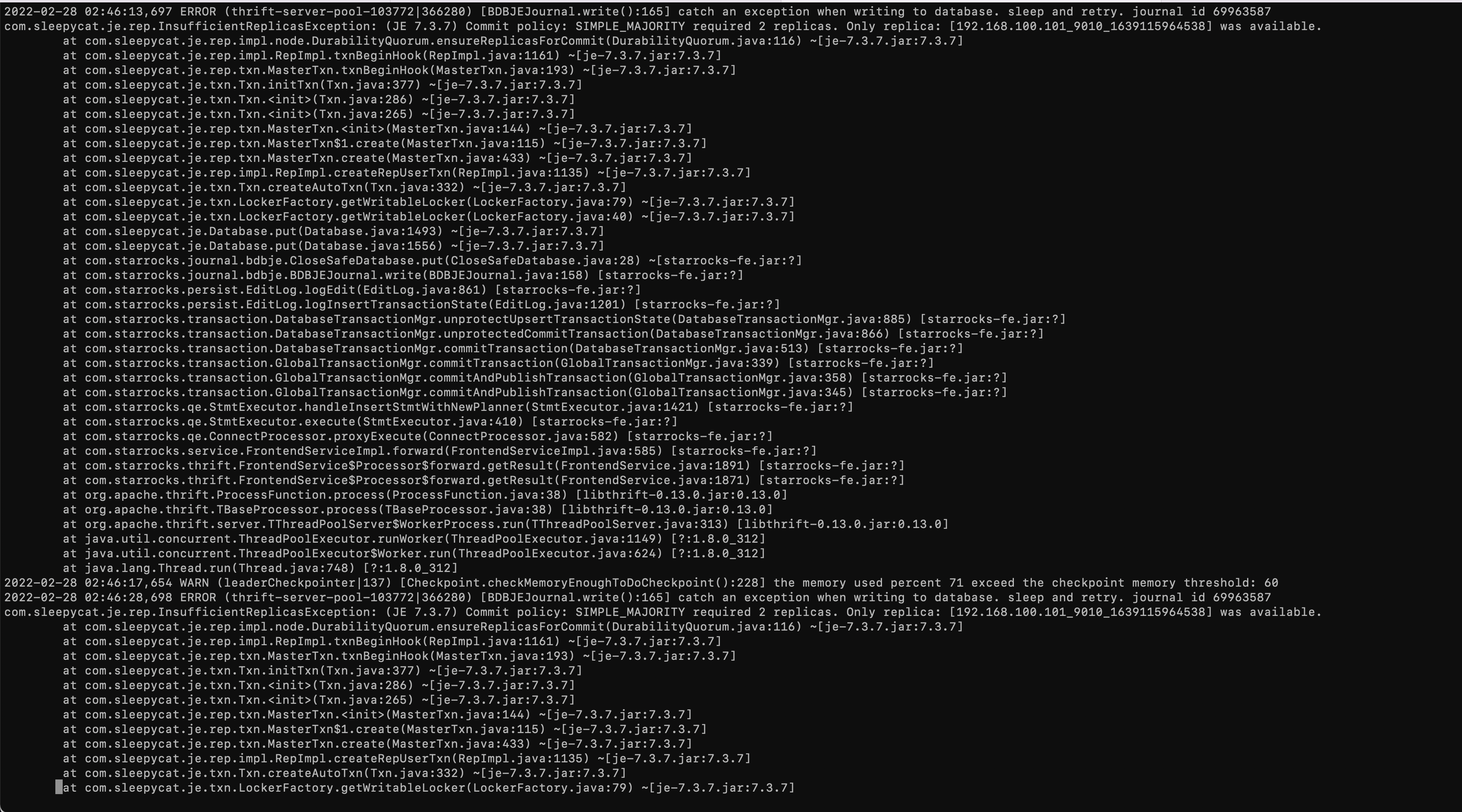
在操作第一台节点时,bin/stop_fe.sh 之后,发现无法启动。随后另外两台fe没有任何操作也自己down掉,查看fe日志显示如下:
fe.warn.log
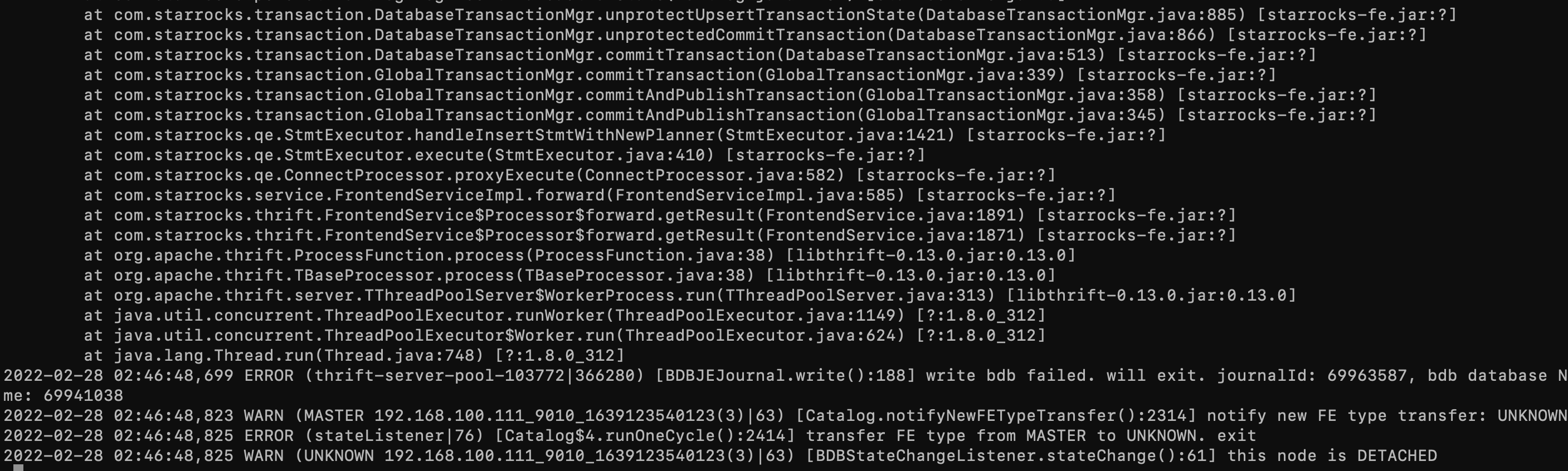
fe.log
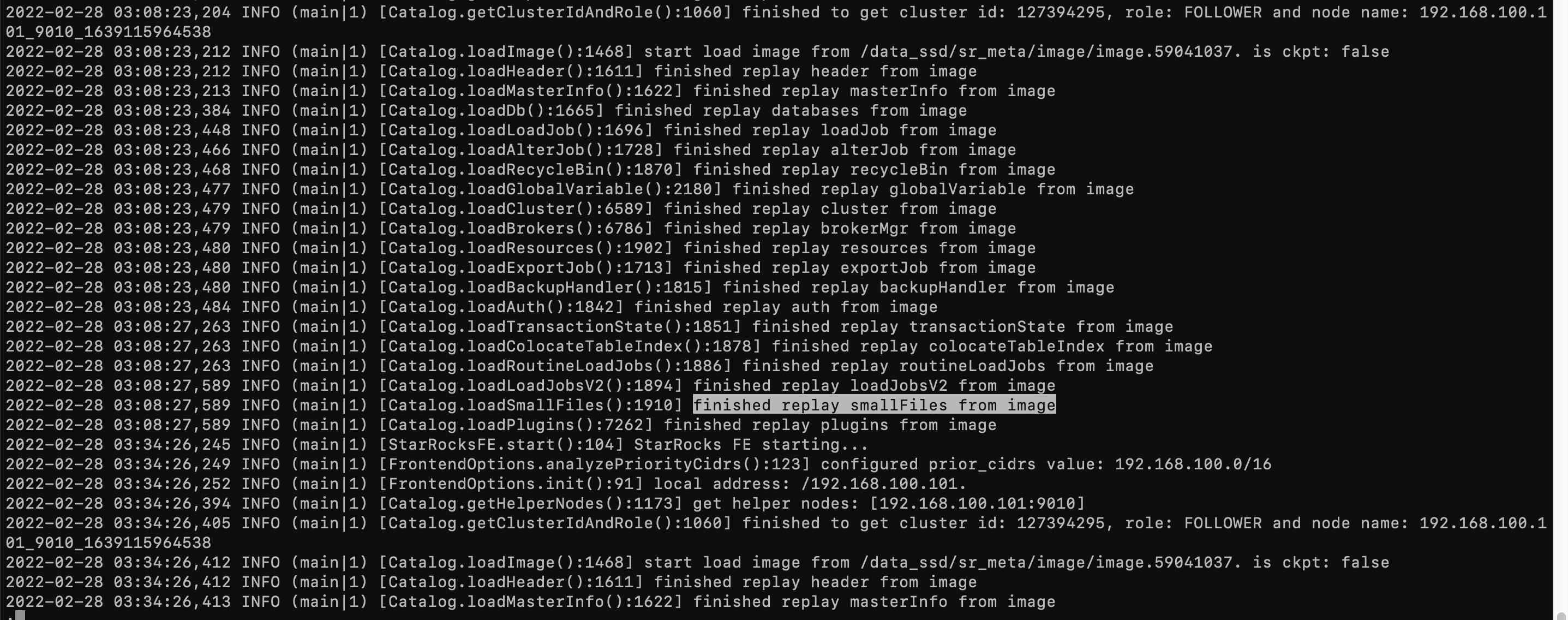
fe.out
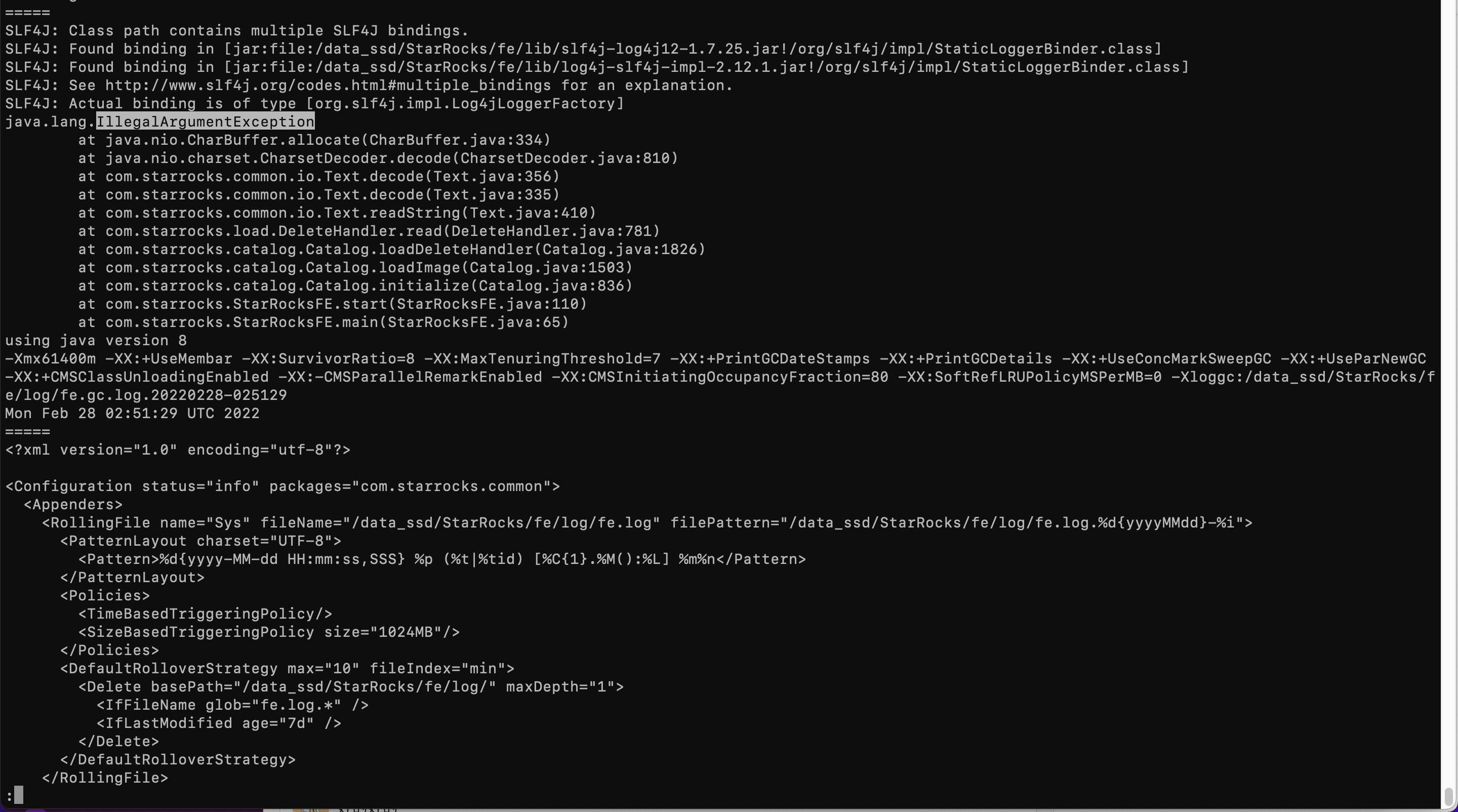
发现日志中并无有效报错信息。
这里有个事情需要插一嘴下,就是之前出现的一些问题:在同一网段其他机器安装完一个单节点测试的sr后 ,发现一个神奇的现象就是 测试节点挂掉之后,会影响线上的服务。线上的节点也会挂掉。
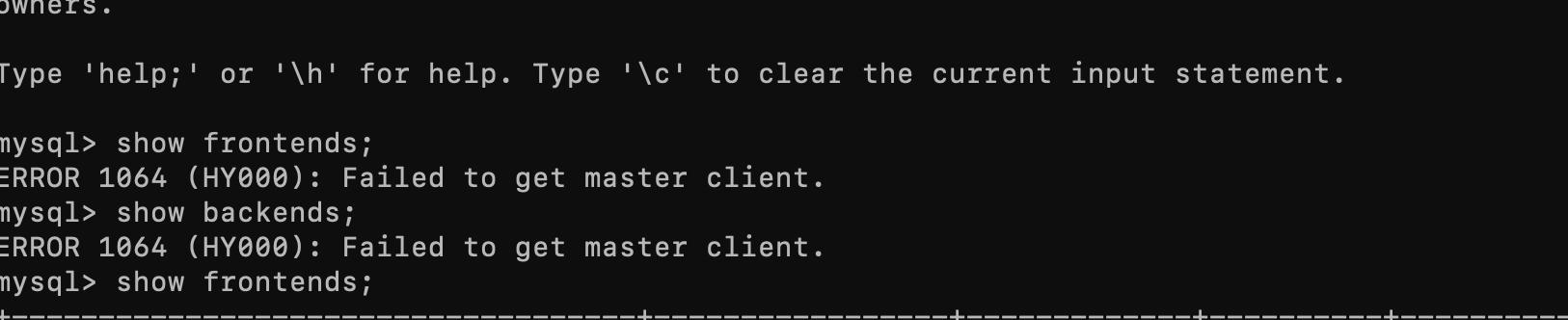
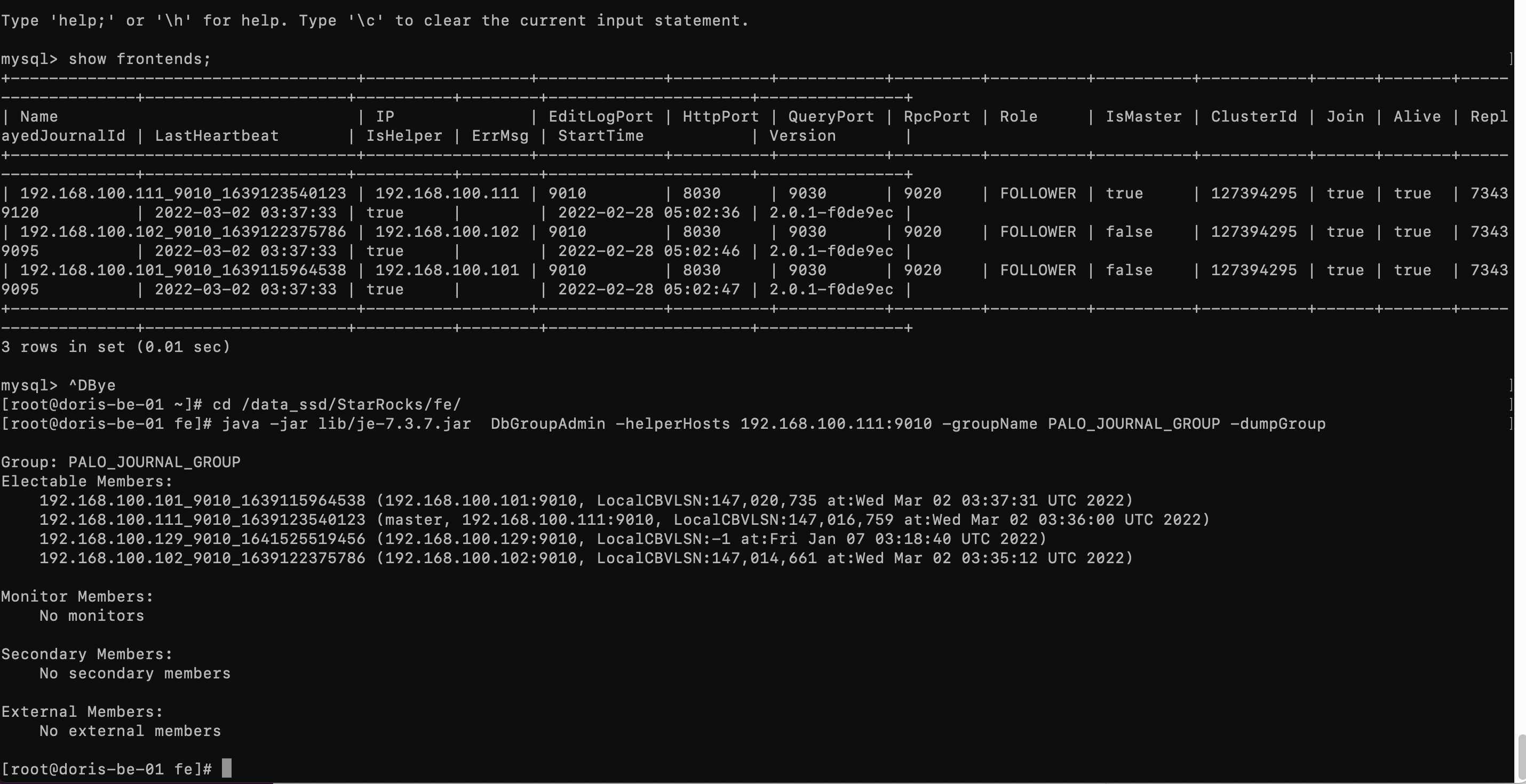
而且后面线上环境出现了 3fe 没有HA的现象,就是其中一台fe down掉 另外两台也不提供服务了。 还有就是不论三个fe 启动顺序是怎样 master始终都是一台节点。从来也没有切换过。。
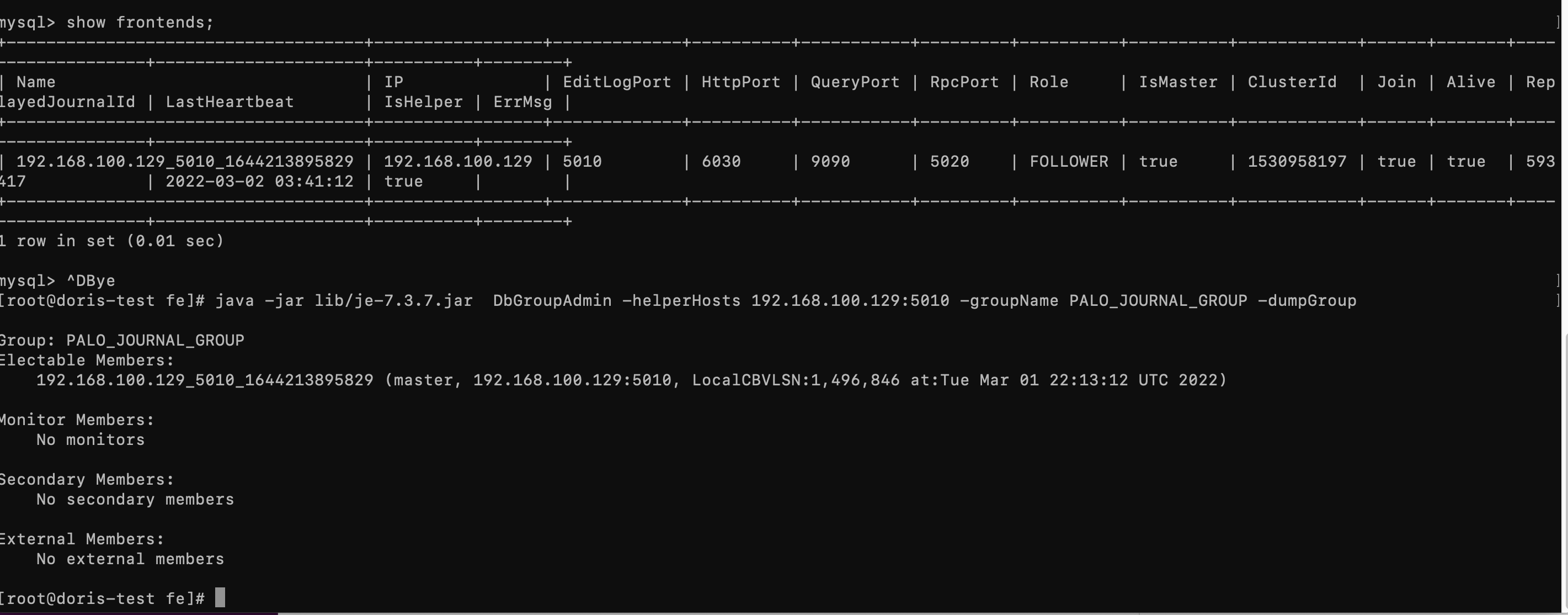
思考会不会也是测试集群链到了线上导致的,随后吧测试节点的fe http端口改掉,发现并没有用。
于是在社群求助 大佬推荐升级试下,
于是将1.19.5 升级为2.0.1版本
升级后分别启动3个fe 等待大概5分钟左右,3fe服务 都恢复正常 。
至此还不太确定 事故原因。 而且不确定2.0.1版本是否还会有 3fe 并不是HA的现象出现。因为是线上服务所以不敢在上面测试。