
Load from mysql to StarRocks
背景
StarRocks提供多种导入方式支持各数据源的数据导入,本文介绍mysql的历史数据导入StarRocks的几种方式以及使用场景
概述:
mysql的数据导入一般建议3种方式导入
- datax导入
适用于离线数据的批量导入,有大量历史数据表导入时推荐此方式
- mysql外表导入
可于离线数据的导入
- cdc工具同步
适用于mysql数据的实时同步
示例demo
下面介绍上述三种导入的使用方法以及demo示例
datax导入
下载安装
#下载解压datax
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
tar -zvxf datax.tar.gz
# writer推荐使用最新插件,下载地址:https://github.com/StarRocks/DataX/releases
tar -zvxf starrockswriter.tar.gz 或 doriswriter.tar.gz
#将starrockswriter放至datax插件目录
mv starrockswriter datax/plugin/writer/
DDL
StarRocks建表
CREATE TABLE dataxtest(
name1
tinyint(4) NULL COMMENT “”,
name2 tinyint(4) NULL COMMENT “”
) ENGINE=OLAP
duplicate KEY( name1 )
COMMENT “OLAP”
DISTRIBUTED BY HASH( name1 ) BUCKETS 3
PROPERTIES (
“replication_num” = “1”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”
);
mysql建表
CREATE TABLE dataxtest3(
NAME1
tinyint(4) NULL COMMENT “”,
NAME 2 tinyint(4) NULL COMMENT “”
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT=‘订单表’
mysql插入数据
Insert into dataxtest values(1,1),(2,2),(3,3),(4,4)
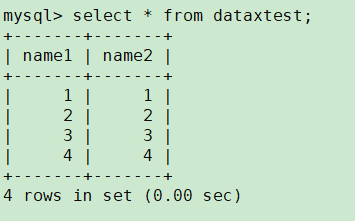
SR创建用户:
CREATE USER datax@'%' IDENTIFIED BY '123456';
grant all on . to 'datax'@'%';
编辑任务:
vim job/mysql.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": ["name1", "name2"],
"connection": [
{
"table": [ "dataxtest"],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/canal"
]
}
]
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"username": "datax",
"password": "123456",
"database": "qcy",
"table": "dataxtest",
"column": ["name1","name2"],
"preSql": [],
"postSql": [],
"jdbcUrl": "jdbc:mysql://127.0.0.1:8012/",
"loadUrl": ["127.0.0.1:8011"],
"loadProps": {}
}
}
}
]
}
}
执行任务
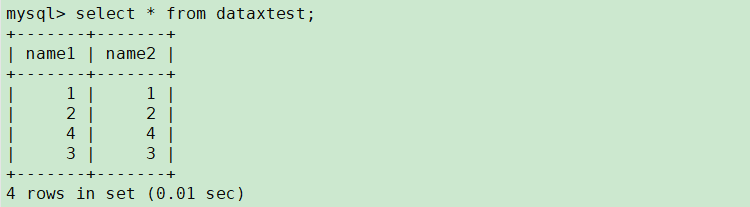
python bin/datax.py --jvm="-Xms6G -Xmx6G" --loglevel=debug job/mysql.json

写入成功,查看数据
myqsl外表导入
内容:
通过建立mysql外表,然后使用insert into 导入starrocks
建表:
CREATE TABLE `lineorder` (
`lo_orderdate` int(11) NOT NULL COMMENT "",
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_linenumber` tinyint(4) NOT NULL COMMENT "",
`lo_custkey` int(11) NOT NULL COMMENT "",
`lo_partkey` int(11) NOT NULL COMMENT "",
`lo_suppkey` int(11) NOT NULL COMMENT "",
`lo_orderpriority` varchar(16) NOT NULL COMMENT "",
`lo_shippriority` tinyint(4) NOT NULL COMMENT "",
`lo_quantity` tinyint(4) NOT NULL COMMENT "",
`lo_extendedprice` int(11) NOT NULL COMMENT "",
`lo_ordtotalprice` int(11) NOT NULL COMMENT "",
`lo_discount` tinyint(4) NOT NULL COMMENT "",
`lo_revenue` int(11) NOT NULL COMMENT "",
`lo_supplycost` int(11) NOT NULL COMMENT "",
`lo_tax` tinyint(4) NOT NULL COMMENT "",
`lo_commitdate` int(11) NOT NULL COMMENT "",
`lo_shipmode` varchar(11) NOT NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`lo_orderdate`, `lo_orderkey`)
COMMENT "OLAP"
PARTITION BY RANGE(`lo_orderdate`)
(PARTITION p1 VALUES [("-2147483648"), ("19930101")),
PARTITION p2 VALUES [("19930101"), ("19940101")),
PARTITION p3 VALUES [("19940101"), ("19950101")),
PARTITION p4 VALUES [("19950101"), ("19960101")),
PARTITION p5 VALUES [("19960101"), ("19970101")),
PARTITION p6 VALUES [("19970101"), ("19980101")),
PARTITION p7 VALUES [("19980101"), ("19990101")))
DISTRIBUTED BY HASH(`lo_orderkey`) BUCKETS 96
PROPERTIES (
"replication_num" = "1",
"colocate_with" = "groupc1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
mysql外表:
CREATE EXTERNAL TABLE lineorder_external_table
(
`lo_orderdate` int(11) NOT NULL COMMENT "",
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_linenumber` tinyint(4) NOT NULL COMMENT "",
`lo_custkey` int(11) NOT NULL COMMENT "",
`lo_partkey` int(11) NOT NULL COMMENT "",
`lo_suppkey` int(11) NOT NULL COMMENT "",
`lo_orderpriority` varchar(16) NOT NULL COMMENT "",
`lo_shippriority` tinyint(4) NOT NULL COMMENT "",
`lo_quantity` tinyint(4) NOT NULL COMMENT "",
`lo_extendedprice` int(11) NOT NULL COMMENT "",
`lo_ordtotalprice` int(11) NOT NULL COMMENT "",
`lo_discount` tinyint(4) NOT NULL COMMENT "",
`lo_revenue` int(11) NOT NULL COMMENT "",
`lo_supplycost` int(11) NOT NULL COMMENT "",
`lo_tax` tinyint(4) NOT NULL COMMENT "",
`lo_commitdate` int(11) NOT NULL COMMENT "",
`lo_shipmode` varchar(11) NOT NULL COMMENT ""
)
ENGINE=mysql
PROPERTIES
(
"host" = "xxx.xxx.xxx.xxx",
"port" = "9030",
"user" = "qcy",
"password" = "123456",
"database" = "ssb_100",
"table" = "lineorder"
);
导入100条数据:

导入成功
导入6亿数据:
导入出错execute timeout

调整参数set query_timeout=3000后重试:

导入成功
cdc工具同步
概述:
主要描述flink-cdc同步mysql数据到sr中的使用实践以及一些问题的解决,原理部分不详细描述
使用flink-cdc+primarykey模型实现数据同步
- 下载 Flink, 推荐使用1.13,最低支持版本1.11。
- 下载 Flink CDC connector,请注意下载对应Flink版本的Flink-MySQL-CDC。
- 下载 Flink StarRocks connector,请注意1.13版本和1.11/1.12版本使用不同的connector.(注意使用的版本) cdc与flink对应版本关系详见:Flink CDC 2.0.0 documentation
- 解压
flink-sql-connector-mysql-cdc-xxx.jar ,
flink-connector-starrocks-xxx.jar 到
flink-xxx/lib/
- 下载 smt.tar.gz
- 解压并修改配置文件
Db 需要修改成MySQL的连接信息。
be_num 需要配置成StarRocks集群的节点数(这个能帮助更合理的设置bucket数量)。
[table-rule.1] 是匹配规则,可以根据正则表达式匹配数据库和表名生成建表的SQL,也可以配置多个规则。仅支持正则匹配,不支持多表使用逗号分开的形式。
flink.starrocks.* 是StarRocks的集群配置信息,参考Flink.
注意: 此处留意ip,端口,库名,表名,正则表达式是否书写正确。另外如果flink设置的是 多并行度 ,由于flink-cdc的机制,需要 开启checkpoint 才能进行数据同步, 不开启checkpoint 只能使用 单并行度 进行同步。开启checkpoint的方式请参考: 失败重试及任务重启
[db]
host = xxx.xxx.xxx.xxx
port = 3306
user = root
password =
[other]
# number of backends in StarRocks
be_num = 3
# `decimal_v3` is supported since StarRocks-1.18.1
use_decimal_v3 = false
# file to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^console_19321.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://xxx.xxx.xxx.xxx:9030
flink.starrocks.load-url= xxx.xxx.xxx.xxx:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
7. 执行starrocks-migrate-tool,所有建表语句都生成在result目录下,此处可将flink-create.1.sql复制一份到flink目录下方便第9步执行
$./starrocks-migrate-tool
$ls result
flink-create.1.sql smt.tar.gz starrocks-create.all.sql
flink-create.all.sql starrocks-create.1.sql
8. 生成StarRocks的表结构,留意命令中端口和脚本是否指定正确
Mysql -hxx.xx.xx.x -P9030 -uroot -p < starrocks-create.1.sql
9. **启动flink-client,** 并生成Flink table并开始同步
bin/sql-client.sh -f flink-create.1.sql
这个执行以后同步任务会持续执行
> 如果是Flink 1.13之前的版本可能无法直接执行脚本,需要逐行提交 注意 记得打开MySQL binlog
10. 观察任务状况
bin/flink list
如果有任务请查看log日志,或者调整conf中的系统配置中内存和slot。
### **失败重试及任务重启**
checkpoints savepoints 简单配置如下
unit: ms
execution.checkpointing.interval: 300000
state.backend: filesystem
state.checkpoints.dir: file:///tmp/flink-checkpoints-directory
state.savepoints.dir: file:///tmp/flink-savepoints-directory
1. 如果是任务运行中的exception导致的任务失败,那么flink系统会根据 flink-conf.yml中的checkpoint配置来进行自动恢复。
2. 如果是用户需要手动停止任务,再恢复任务的话,需要先在 flink-conf.yml 配置 `state.savepoints.dir: [file://或hdfs://]/home/user/savepoints_dir` 后按以下两种场景来操作:
1. 用户现场具备 `停止mysql增删改` 的条件(即会丢失 `停止 ~ 再次重启` 之间的数据):
1. 使用如上描述的sql-client方式创建任务后获得jobid
2. 停止 mysql 的 `增删改` 操作
3. flink中停止对应的jobid
4. 对mysql或starrocks进行变更操作
5. 修改 flink-cdc 的src table配置增加 `'scan.startup.mode'='latest-offset'`
6. 重复 **i.** 的步骤提交任务
7. 恢复 mysql 的正常使用即可。
2. 用户现场不具备控制mysql侧的条件,并且希望再次重启后的任务可以不丢失任何数据:
1. 使用 `./flink run -c com.starrocks.connector.flink.tools.ExecuteSQL flink-connector-starrocks-xxxx.jar -f flink-create.all.sql` 提交任务后获取jobid
2. 停止任务则执行: `./flink stop jobid` 此时会提示 savepoints 保存的目录
3. 对mysql或starrocks进行变更操作
4. 如果修改了表结构则需要使用smt工具重新生成 `flink-create.all.sql` 文件
5. 再次启动任务 `./flink run -c com.starrocks.connector.flink.tools.ExecuteSQL -s savepoints_dir/savepoints-xxxxxxxx flink-connector-starrocks-xxxx.jar -f flink-create.all.sql` 即可从任务停止时的offset继续消费binlog的数据
### 注意事项
1. 如果有多组规则,需要给每一组规则匹配database,table和 flink-connector的配置。
[table-rule.1]
pattern to match databases for setting properties
database = ^console_19321.*$
pattern to match tables for setting properties
table = ^.*$
############################################
flink sink configurations
DO NOT set connector, table-name, database-name, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://xxx.xxx.xxx.xxx:9030
flink.starrocks.load-url= xxx.xxx.xxx.xxx:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
[table-rule.2]
pattern to match databases for setting properties
database = ^database2.*$
pattern to match tables for setting properties
table = ^.*$
############################################
flink sink configurations
DO NOT set connector, table-name, database-name, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://xxx.xxx.xxx.xxx:9030
flink.starrocks.load-url= xxx.xxx.xxx.xxx:8030
flink.starrocks.username=root
flink.starrocks.password=
如果导入数据不方便选出合适的分隔符可以考虑使用Json格式,但是会有一定的性能损失,使用方法:用以下参数替换flink.starrocks.sink.properties.column_separator和flink.starrocks.sink.properties.row_delimiter参数
flink.starrocks.sink.properties.strip_outer_array=true
flink.starrocks.sink.properties.format=json
```
2. Flink.starrocks.sink 的参数可以参考[上文](https://docs.starrocks.com/zh-cn/main/loading/Flink-connector-starrocks##使用方式),比如可以给不同的规则配置不同的导入频率等参数。
3. 针对分库分表的大表可以单独配置一个规则,比如:有两个数据库 edu_db_1,edu_db_2,每个数据库下面分别有course_1,course_2 两张表,并且所有表的数据结构都是相同的,通过如下配置把他们导入StarRocks的一张表中进行分析。
```
[table-rule.3]
# pattern to match databases for setting properties
database = ^edu_db_[0-9]*$
# pattern to match tables for setting properties
table = ^course_[0-9]*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://xxx.xxx.xxx.xxx:9030
flink.starrocks.load-url= xxx.xxx.xxx.xxx:8030
flink.starrocks.username=root
flink.starrocks.password=
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=5000
```
这样会自动生成一个多对一的导入关系,在StarRocks默认生成的表名是 course__auto_shard,也可以自行在生成的配置文件中修改。
4. 如果在sql-client中命令行执行建表和同步任务,需要做对'\'字符进行转义
```
'sink.properties.column_separator' = '\\x01'
'sink.properties.row_delimiter' = '\\x02'
```
5. 如何开启MySQL binlog
修改/etc/my.cnf
```
#开启binlog日志
log-bin=/var/lib/mysql/mysql-bin
#log_bin=ON
##binlog日志的基本文件名
#log_bin_basename=/var/lib/mysql/mysql-bin
##binlog文件的索引文件,管理所有binlog文件
#log_bin_index=/var/lib/mysql/mysql-bin.index
#配置serverid
server-id=1
binlog_format = row
```
重启mysqld,然后可以通过 SHOW VARIABLES LIKE 'log_bin'; 确认是否已经打开。
6. 使用flink-cdc2.1.0版本导入数据报错“ The connection property ‘zeroDateTimeBehavior’ only accepts values of the form: ‘exception’, ‘round’ or ‘convertToNull’. The value ‘CONVERT_TO_NULL’ is not in this set”
1. 解决方案可参考[flink-cdc2.1.0版本 导入数据报错](https://forum.mirrorship.cn/t/topic/1161) 该文档中解决方案,下载使用新版flink-cdc