
部署场景问题梳理
FE
1. 进程查不到
查看fe.warning日志,查找是否有以下报错:
1.1 端口占用
关键字:port xxx is used
解决方法:修改fe.conf中相应被占用端口为闲置端口,重启即可。
1.2 缺少meta目录
关键字:meta not exist
解决方法:在fe安装目录下新建meta目录,然后重启
1.3 jdk环境错误
关键字:Could not initialize class org.apache.doris.rpc.BackendServiceProxy
解决方法:检查是否使用的是jre,如果使用的jre换成jdk即可,推荐使用oraclejdk版本1.8+。
2. fe进程存在,但是fe状态false
查看fe.warning日志,查找是否有以下报错:
2.1 Fe身份识别失败
关键字:Fe type:unknown ,is ready :false
2.1.1 是否没有add相应节点到集群里。
关键字: current node is not added to the cluster, will exit
解决方案:非第一台启动的fe节点首次加入集群时需要在集群中add相应节点信息,
使用MySQL客户端连接已有的FE, 添加新实例的信息,信息包括角色、ip、port:
mysql> ALTER SYSTEM ADD FOLLOWER "host:port";
或
mysql> ALTER SYSTEM ADD OBSERVER "host:port";
2.1.2 集群有add信息,但是ip识别出错
关键字:backend ip saved in master does not equal to backend local ip xxx vs 127.0.0.1
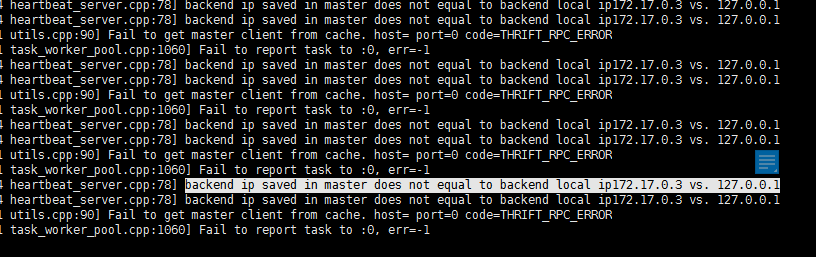
解决方案: 检查机器是否多网卡多ip,需要在fe.conf中配置priority_networks为xxx,然后重启
2.1.3 服务器同步超时
关键字:this replica exceeds max peimissible delta:5000ms
故障分析:fe.warning一直刷Fe type:unknown ,is ready :false,没其他信息时,查看jbd信息是否有所示错误。路径/xx/StarRocks-xxx/fe/meta/bdb/je.info.0
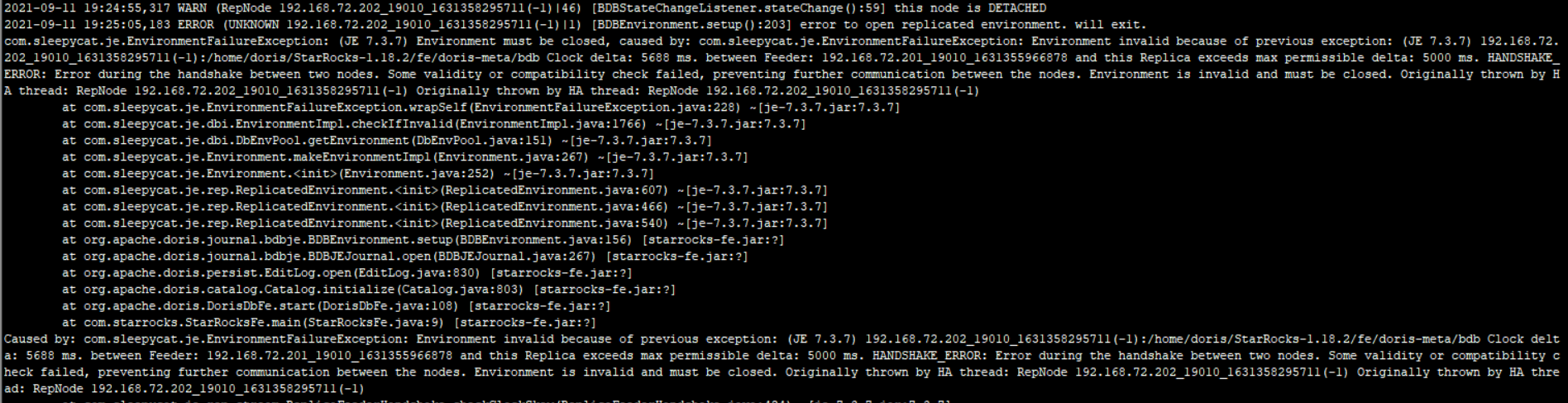
解决方案:
需要同步集群机器时间,默认超过5s认为同步失败,建议开启utc校准后重启fe。
2.1.4 网络故障,连接失败
关键字:connection refused
解决方案:确认集群间http_port时互相能ping通的。有权限问题联系集群运维人员开通后重启。
2.2 FE transfer成功,但是show frontends显示false
2.2.1 Fe type:master,is ready :true,但是连接其他fe节点show forntends显示状态false
是因为非第一台启动的fe节点首次加入集群时需要加上–helper启动,第一次启动不加–helper会把自己当作master启动,与其他节点通信失败,此时需要清空meta目录。然后加上–helper参数重新启动。
./bin/start_fe.sh --helper host:port --daemon
host为helper节点的IP,如果有多个IP,需要选取priority_networks里的IP。port为edit_log_port,默认为9010。
当FE再次启动时,无须指定–helper参数,因为FE已经将其他FE的配置信息存储于本地目录, 因此可直接启动:
./bin/start_fe.sh --daemon
2.2.2 Fe type:follower,is ready :true,但是连接其他fe节点show forntends显示状态false
查看bdb文件大小,若内存使用超过机器内存的60%,则不会做checkpoint,bdb文件夹会增大,然后初次启动读取bdb文件过长,这个过程会导致fe状态false不可用,此时需要调整fe 的jvm大小,修改fe.conf中的JAVA_OPTS,然后重启。

BE
1. 进程查不到
查看be.warning日志,查找是否有以下报错:
1.1 端口占用
关键字1:port xxx is used;fail to report disk state to xxx:9030,err=-1

解决方法:修改be.conf中相应被占用端口为闲置端口,重启即可。
1.2 缺少storage目录
关键字:storage not exist
解决方法:在be安装目录下新建storage目录,然后重启
1.3 http_service启动失败
关键字:Be http service did not start correctly,exiting
解决方法:该问题是be webservice端口被占用,可以尝试修改be.conf中的相关端口并重启。如果多次修改没有被占用的端口也重复报错,检查是否装有yarn等程序,确认监听端口选择修改监听规则,或者be的端口选取范围绕过即可。
1.4 jdk环境错误
关键字:Could not initialize class org.apache.doris.rpc.BackendServiceProxy
解决方法:检查是否使用的是jre,如果使用的jre换成jdk即可,推荐使用oraclejdk版本1.8+。
2. be进程存在,但是be不可用
2.1 是否没有add相应节点到集群里。
关键字: show backends 显示empty
解决方案:通过mysql客户端添加BE节点:
mysql> ALTER SYSTEM ADD BACKEND "host:port";
这里IP地址为和priority_networks设置匹配的IP,portheartbeat_service_port,默认为9050
2.2 网络故障,连接失败
关键字:connection refused
解决方案:确认集群间http_port时互相能ping通的。有权限问题联系集群运维人员开通后重启。
2.3 磁盘不足
关键字:Failed to get scan range, no queryable replica found in tablet: 11903
解决方案:定位磁盘不足,需要修改be.conf中的storage_root_path,可以指定多个目录,用;隔开。